
信息来源:阮一峰每周分享
文章来源:Types are moving to the right
If you take a look at statically-typed programming languages that are still popular today but were designed in the previous century, before the turn of the millennium, you’d notice that most of them and, at the same time, the more popular and mainstream ones, like C (circa 1972), C++ (1985), and Java (1995), write types to the left of names:
如果你环顾一下当下正流行但却是上个世纪(也就是千禧年之前)设计的静态语言的话,你就会留意到他们大多数,同时也是更受欢迎和主流的那些比如 C语言(大约1972年)、C++(1985)以及Java(1995),是在名称左侧书写类型的:
1 | Dog fido = ... |
It reads nicely when you write a lot of declarations, too:
当你编写很多个声明时,这种写法可读性是很好的:
1 | int count = ... |
However, if you take a look at modern languages, designed in XXI Century, you cannot help but notice that the languages with some popularity increasingly put types to the right of names¹:
但是,如果你看一下当代的编程语言,也就是在21世纪被创造出来的编程语言,你不禁会发现一些受欢迎的编程语言将类型写在了变量名前面:
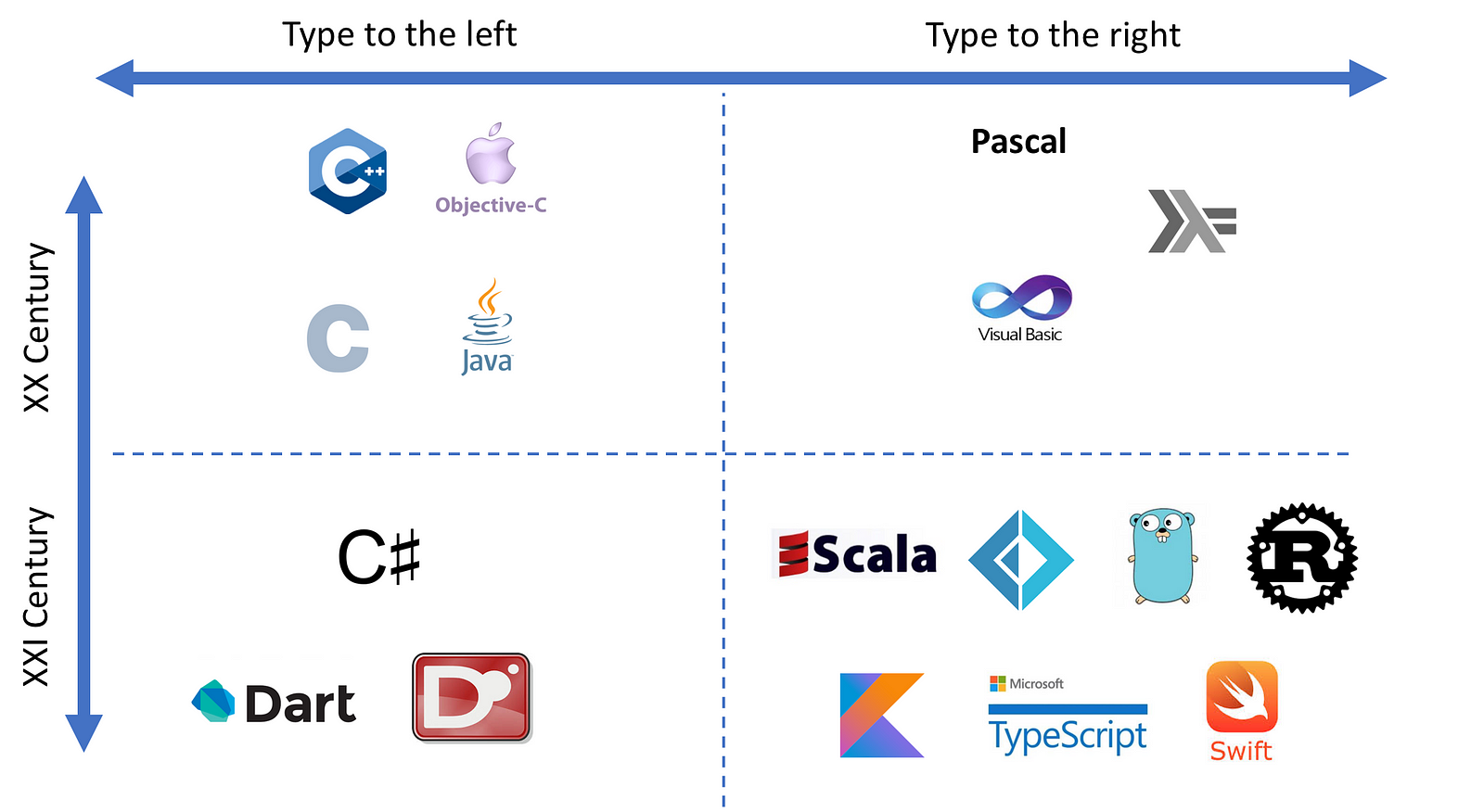
Why is it happening? It might seem strange and inconvenient to any developer who got used to the last-century type-name style, but modern language designers still do it despite the risk of breaking with tradition. Are they all Pascal fans or what?
为什么会这样?这对于已经习惯了上个世纪的类型书写方式的开发人员来说或许会看起来比较奇怪和不方便,但是当代编程语言的设计者在尽管可能会传统的风险的情况下依然选择这样设计。他们都是Pascal的粉丝还是有其他什么原因呢?
Here is a plausible explanation. First of all, it has nothing to do with legacy of Pascal (circa 1970) or even with Visual Basic (1991) for that matter. The real answer is that we have entered the age of type inference.
这里有一个似是而非的解释。首先,这样设计与 Pascal (1970)甚至 Visual Basic 无关,真正的原因是我们进入了 类型推断 的时代。
Type inference, which used to be a niche feature in programming language design, is now entering mainstream. It is appearing in our old programming languages where we can now omit types using var and auto keywords, too². Even in established programming languages we start seeing code like this:
类型推断曾是编程语言设计中的一个小众特性,现在正在进入主流。他出现在我们旧的编程语言中,而现在我们可以使用 var 和 auto 关键字省略类型。即使是在已经存在的编程语言中我们也可以看到类似这样的代码:
1 | var count = ... |
Woot! That’s nice and aligns, pleasure for our eyes to see. But what happens when the type is too complex for type inference or when it needs to be occasionally spelled ou spelled out for human reader to understand? Behold:
哇,这看起来很不错,很整齐,一眼看上去很赏心悦目。但是当被推断的类型非常复杂时或者当 偶尔 需要写出给人看的代码时会发生什么情况呢?看啊:
1 | var count = ... |
Uh… that breaks the whole code-reading flow. So, if you are designing a programming language in the age of type inference from scratch, then you solve it by putting an optional type annotation to the right of the name:
额… 这完全失去代码的可读性了嘛。因此,如果你你是从头开始设计类型推理时代的编程语言,那么你可以在变量名右侧添加可选的类型注释来解决可读性的问题:
1 | var count = ... |
Now it looks great again. That is essentially the way it is done in Scala (2004), F# (2005), Go (2009), Rust (2010), Kotlin (2011), TypeScript (2012), and Swift (2014) programming languages. There are many syntactic differences between them, but one thing is common — name-type order:
现在代码的可读性有恢复啦。这实际上就是 Scala(2004), F#(2005), Go(2009), Rust(2010), Kotlin(2011), TypeScript(2012) 和 Swift(2014) 这些编程语言中类型的定义方式。
1 | fido Dog |
This way of writing code is on the rise now. Is it going to become mainstream in the future? That is hard to tell for sure, but the trend does look so.
这种代码编写的方式正在变得流行,它会在将来成为主流吗?这很难说清楚,但是从趋势来看时很有可能的。
More on programming languages 更多关于编程语言的内容
Despite the age, I still consider Java to be one of the greatest languages of the XXI Century. Read more in my “Tribute to Java”.
尽管已经年代久远,我仍然认为 Java 是 21 世纪最伟大的语言之一,在我 “Tribute to Java” 中可以阅读更多相关内容。
If you liked this story then you might also like my story on “Dealing with absence of value”.
如果你喜欢这个故事那么你应该也会喜欢 “Dealing with absence of value” 这个故事。