
记录一些笔记,将自己看到听到的有关数据结构与算法的内容都记录下来。这是关于排序的部分。
声明:这里说的排序都是以数组为待排序对象
原地排序是指空间复杂度为O(1)的排序算法。
如果待排序序列中的相等元素经过排序后没有改变他们之间的相对顺序,那么这个排序算法就是稳定的,反之这个排序算法就是不稳定的。
冒泡排序
冒泡排序思想:略。
冒泡、插入、选择排序空间复杂度都是O(1),都是原地排序算法。
冒泡排序的优化之一:当某次冒泡没有进行数据交换时,序列就已经有序了,冒泡就可以结束了。
冒泡实现:
1 | // 冒泡排序,a 表示数组,n 表示数组大小 |
由于冒泡只交换大小不等的两个相邻元素,所以相等的两个元素的相对位置是不会改变的,因此是稳定排序。
冒泡时间复杂度:最好情况是序列已经有序,只需进行一次冒泡,因此是O(n),最坏情况是序列完全逆序,需要进行n次冒泡,所以是O(n²)。平均时间复杂度也是O(n²)。
插入排序
插入排序思想是将待排序数组分成已排序和待排序两个区间,初始已排序区间只有一个元素,就是数组第一个元素,在待排序区间中依次取出数据,插入到已排序区间的正确位置,直到待排序区间没有元素。
与冒泡一样,也包含数据的比较和数组元素的移动,只不过冒泡是只移动一个元素,插入是要移动多个元素。
插入排序实现:
1 | // 插入排序,a 表示数组,n 表示数组大小 |
插入排序是原地排序,因为没有创建额外空间,空间复杂度是O(1).
插入排序是稳定的,因为两个相等的元素不会进行位置交换。
时间复杂度最好情况是数据有序,只需便利n-1次未排序区间的数据即可完成排序,因此时间复杂度是O(n),最坏情况是数组完全逆序,每次都需要移动数据,时间复杂度是O(n²)。往数组中插入一个数据的平均时间复杂度是O(n),因此这里循环n次插入操作时间复杂度就是O(n²)。
选择排序
选择排序也分已排序和未排序区间,但是与插入排序不同的是,选择排序会在未排序区间中找到最小值后放入未排序区间末尾,放到末尾的操作是通过元素交换完成的。
选择排序是非稳定的,因为涉及到夸元素交换,可能会导致数据相等的两个元素位置互换。比如 4,5,4,2,8.
冒泡与插入比较
- 冒泡书写比较复杂,数据交换需要三部操作,插入只需要一步。
1 | 冒泡排序中数据的交换操作: |
归并排序
- 归并排序思想:分而治之,将数组从中间分成前后两部分,依次递归下去,分别对前后两部分排序,最终再合并到一起。
1 | 递推公式: |
归并排序实现
1 | public class MergeSort { |
归并排序是稳定的
归并排序时间复杂度是O(nlogn).
归并排序空间复杂度是O(n)
快速排序
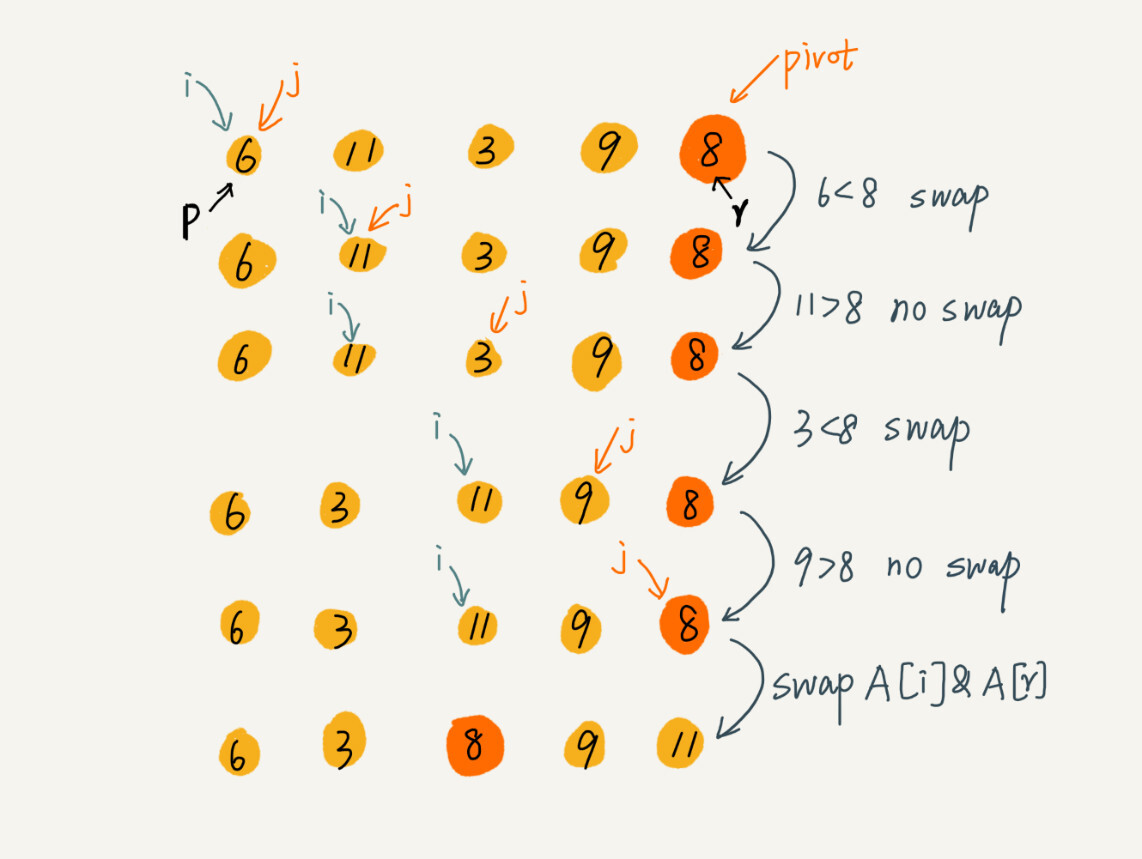
- 排序思想:从数组(加入下标从p到r)中选择任意一个元素作为分区点piovt,遍历p到r之间的数据,将小于pivot的放到左边,大于pivot的放到右边,pivot放到中间,然后递归继续对两个分区继续分,直到区间大小为1.
1 | public class QuickSort { |
其中partition函数是重点,为了不使用额外空间,这里有个小技巧就是使用交换元素的方法进行排序。每次处理都将小于pivot的数放到已处理区域,最后再将pivot放到合适的位置上。
归并排序不是稳定的,因为涉及到不相邻元素的交换操作。
归并排序与快速排序的区别:
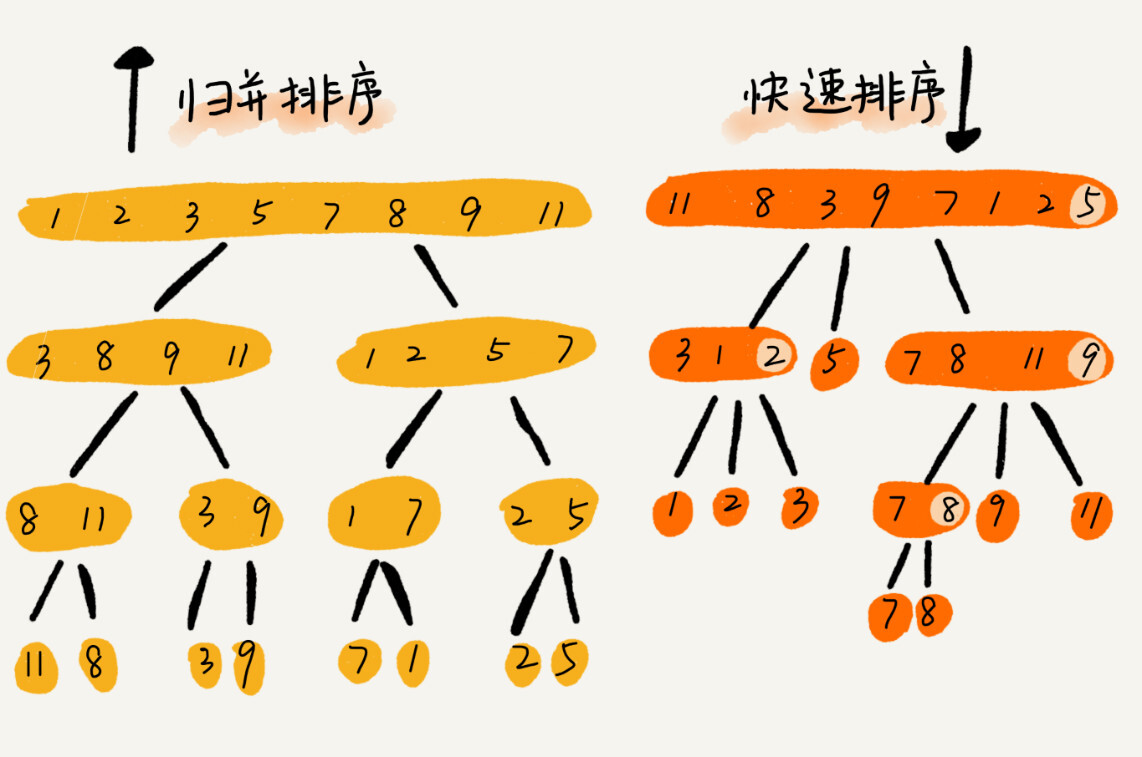
归并排序的处理是自下而上的,快速排序是自上而下的。
归并不是原地排序,因为最终的合并函数无法原地执行,但是快排可以通过巧妙的方法实现原地排序,解决了占用内存过大的问题。
快排时间复杂度也是O(nlogn)
问题
如何在O(n)时间复杂度内求解无序数组中第K大元素?
选择数组区间A[0…n-1]的最后一个元素A[n-1]作为pivot,对数组进行原地分区,这样数组就分成了三部分,A[0…p-1],A[p],A[p+1…n-1]。如果p+1=K,那么A[p]就是要求解的元素,如果K>p+1,说明第K大元素出现在A[p+1…n-1]中,再按照上面的思路进行划分查找。同理如果 K 小于 p+1 ,就在A[0…p-1]中查找。
有10个接口访问日志文件,每个日志文件大小是300M,每个日志文件内数据按照时间戳从小到大排序,希望将这个10个文件合并成一个文件,合并之后时间戳仍按从小到大的顺序排序,如果处理这个任务的机器物理内存只有1G,怎么解决这个问题?
创建10个io流,分别从10个文件读取数据,每次读取40M的数据,进行归并排序中的合并操作,然后继续读取数据,知道数据读完。时间复杂度是O(n),空间复杂度是O(1).