
集群环境
操作系统:RedHat
内存:32G
Hadoop版本:2.7.6
Hive版本:1.2.2
有关Hadoop的安装,HDFS和YARN的配置可以参考我写的 配置本地Hadoop环境,另外Hive的常用函数可以参考我的另一篇文章 Hive常用函数总结 。
相关数据资源
可以从我的百度云盘这个地址下载相关数据资源信息。然后将这些资源信息放到HDFS上,在后续创建Hive表的过程中根据你实际放置的HDFS路径修改location相关的内容即可。
Hive解决了什么问题
从MR到Hive

Hadoop的核心是HDFS和MapReduce计算框架。HDFS是分布式文件系统,是Hadoop文件存储和管理的基础。MR是计算引擎,承担Hadoop下的计算任务。
Sqoop:是关系型数据库与Hadoop之间的数据传输工具。
FLume:是日志收集系统
Zookeeper:分布式协作服务
HBase:列存数据库
Mahout:用于数据挖掘
Pig:服务于流计算
Hive:数据仓库工具
HDFS解决了文件分布式存储的问题。
MapReduce解决了数据处理分布式计算的问题
Hive解决了什么问题呢?—- 化繁为简
Hive将开发人员从手写MapReduce程序的麻烦过程中解放出来,编写SQL程序即可完成MR任务。
化繁为简的Hive
![]()
Hive所作的工作不是替代MapReduce,而是将SQL语句翻译成MapReduce任务执行,它提供了一个接口层,供用户使用SQL来调用MapReduce,这极大提高了数据分析人员和开发人员的工作效率。
Hive擅长什么
Hive的优势
简单容易上手
Hive使用类SQL语言,有关系型数据库使用经验的人都可以平滑过渡到Hive,非程序员也可以快速上手使用。
开发快速
Hive清洗和分析数据的效率很高,Hive出现之前,数据处理工作需要交给熟悉MR程序的开发人员才能完成,而且MR程序的编写工作量非常大,Hive出现后,使用类SQL语言直接操作数据,大大提高了开发速度。
适合大规模数据的处理
Hive最终会将SQL语句翻译成MR程序执行,所以它能处理大规模数据。
Hive的局限
延迟高
即使数据量很小,也需要很长时间才能完成Hive的一个操作,这是由Hadoop执行引擎的特点决定的。
不支持DELETE/UPDATE等事务处理
这是HDFS的特性决定的,HDFS适合一次写入多次读取的情况,因此不能通过Hive完成DELETE/UPDATE等事务处理操作。
Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算
Hive的适用场景
- 海量日志分析
日志数据量是非常庞大的,一个中型网站每天的日志数据量可达数十GB,这样的数据量式用单机处理会很吃力,需要式用分布式处理系统。另外日志数据产生后不会修改,满足Hive式用条件,一般情况下离线数据分析能满足很大一部分业务需求。

日志数据通过flume收集到HDFS上,然后经过MR清洗(如清除一些异常日志),重新存放到HDFS,最后经过Hive处理和统计,为最终业务需要服务。
- 海量结构化数据分析
业务数据库中的表往往是针对线上业务而设计的,对统计分析需求往往并不友好,而且通常也不满足高并发量的需求。

要进行数据分析通常是先使用Sqoop工具将关系型数据库中的数据导入到HDFS,之后根据统计分析业务需要,通过Hive对数据进行处理,存储成方便后续业务分析的格式。这就是数据仓库的场景。
Hive数据结构与数据仓库
数据仓库
数据仓库是一个:面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合。用于支持管理层决策。
传统数据仓库

早期数据仓库建立在数据库之上,依托中央数据库,由于中央数据库运行于单机上,存储、计算和扩展能力都受到严重制约,已经不满足现在数据处理的需求,数据达到PB级时,传统数据库基本无法获得很好的性能。

Hive构建的数据仓库建立在Hadoop之上,将从数据源收集的数据会存放在HDFS后,Hive将HDFS上的数据映射为数据库,并以MapReduce任务的形式进行计算,为接下来的数据报表和分析提供服务。Hive可以满足大部分数据分析的需求,且拓展能力很强。
Hive架构(3+1)

Hive组成模块:
用户接口模块(User Interface):用于实现对Hive的访问
CLI:命令行方式
JDBC:提供java编程接口
HWI(HiveWebUI):网页形式提供访问接口
元数据模块(MetaStore):是一个数据库,可以是Hive自带数据库也可是外部数据库,常用MySQL。Hive的数据存储格式可以由用户自己定义,元数据记录了数据存储的格式,对照元数据信息,Hive才能将HDFS上的数据映射为有意义的数据表。
驱动模块(Drivers):驱动模块包括编译器、优化器、执行器等,负责将SQL语句转化成MapReduce任务。
关联模块
- Hadoop:Hive并不能独立完成数据处理工作,它将SQL转化成MapReduce任务后交给Hadoop处理。
Hive运行流程

Hive通过用户接口获得用户提交的查询任务,将其交给Driver模块。
Driver模块利用解析器解析查询语句获得用户任务。
编译器根据用户任务到MetaStore查询元数据信息。
编译器获得云信息后对任务进行编译,生成逻辑查询计划。
之后编译器将逻辑查询计划转为物理执行计划
Driver模块最后将物理计划转交给Hadooop执行。
Hadoop将执行结果返回给Hive,Hive通过用户接口返回数据结果。
数据模型与元数据
Hive数据模型
Hive数据模型包括:
Database 数据库:Hive数据模型的概念等同于关系型数据库的schema,是数据库的组织和结构,描述了数据库的表、列、视图等对象的信息
Table 表:Hive中表的概念与关系型数据库中表的概念一致
Partition 分区:类似关系数据中的表分区,Hive中同一分区的数据会放到同一目录下,使用分区在一些条件下能够提高计算效率,同一分区的数据可以进一步划分为桶,类似于子分区。
Bucket 桶:分区的数据可以进一步划分为桶,类似于子分区。
与关系数据库的区别在于Hive的表可以分为内部表和外部表
内部表Drop的时候会删除HDFS上的数据,适用于中间表等不需要从外部导入数据的情况。
外部表Drop时候不会删除HDFS上的数据,适用于将外部数据映射到表中的源表。
元数据
描述数据的数据

元数据是对具体数据的一种格式化,Hive将SQL翻译成MapReduce的过程需要结合元数据来完成,Hive的元数据存储在关系型数据库中,这个数据库可以是Hive自带的derby,也可以是外部的MySQL数据库。
Hive元数据表
| 字段 | 用途 |
|---|---|
| VERSION | 存储Hive版本的元数据表 |
| DBS、DATABASE_PARAMS | Hive数据库相关的源数据表 |
| TBLS、TBL_PRIVS、TABLE_PARAMS | Hive表和视图相关的元数据表 |
| SDS、SD_PARAMS、SERDES、SERDE_PARAMS | Hive文件存储信息相关的元数据表 |
注:
DBS中存储Hive中所有数据库的基本信息。
DATABASE_PARAMS存储数据库的相关参数。
不太常用的源数据表
| 字段 | 用途 |
|---|---|
| COLUMNS_V2 | 表字段相关元数据 |
| PARTITIONS、PARTITION_KEYS、PARTITION_KEY_VALS、PARTITION_PARAMS | 数据库权限信息表 |
| DB_PRIVS | 数据库权限信息表 |
| IDXS | 存储Hive索引相关元信息 |
| INDEX_PARAMS | 索引相关的属性信息 |
| TAB_COL_STATS | 表字段的统计信息 |
| TBL_COL_PRIVS | 表字段的授权信息 |
| PART_PRIVS | 分区的授权信息 |
| PART_COL_STATS | 分区字段的统计信息 |
| PART_COL_PRIVS | 分区字段的权限信息 |
| FUNCS | 用户注册的函数信息 |
| FUNC_RU | 用户注册函数的资源信息 |
Hive安装与配置
Hive安装依赖
Hadoop
元数据存储
内嵌数据库Derby —-内嵌模式
外部数据库
本地数据库 —-本地模式
远程数据库 —-远程模式
三种配置模式的特点和区别
内嵌模式:内嵌的Derby数据库存储元数据,一次只能连接一个客户端
本地模式:外部数据库存储元数据,metastore服务和hive运行在同一个进程。
远程模式:外部数据库存储元数据,metastore服务和hive运行在不同的进程。
在hive-site.xml中可以通过jdbcURL、驱动、用户名、密码等配置信息,设置不同的模式。
生产环境下一般使用远程模式,测试环境下一般使用内嵌模式。
Hive安装与配置
- Hive安装包结构
| 文件夹 | 存放内容 |
|---|---|
| bin | 执行文件目录 |
| conf | 配置文件目录 |
| examples | 样例目录 |
| hcatalog | 表和数据管理层 |
| lib | jar包目录 |
| scripts | 数据库脚本目录 |
| LICENSE | 许可文件 |
| NOTICE | 版本信息 |
| README.txt | 说明文件 |
| RELEASE_NOTES.txt | 更新历史 |
Hive Cli启动流程
bin/hive-config.sh初始化配置信息
conf/hive-env.sh初始化一些环境变量
检查hive-exec-*.jar, hive-metastore-*.jar, hive-cli-*.jar几个主要jar包是否存在。
添加hadoop相关classpath
执行lib/hive-service-x.x.x.jar
下载、解压、重命名Hive
1
2
3[1015146591@bigdata4 apps]$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
[1015146591@bigdata4 apps]$ tar xzvf apache-hive-1.2.2-bin.tar.gz -C /mnt/home/1015146591/apps
[1015146591@bigdata4 apps]$ mv apache-hive-1.2.2-bin/ hive-1.2.2修改配置文件conf/hive-env.sh(这里主要是配置HADOOP_HOME,如果之前配置过HADOOP_HOME,这里无需配置hive-env.sh),配置HADOOP_HOME。
1
2# 将改行注释去掉,配置正确的Hadoop目录即可
HADOOP_HOME=${bin}/../../hadoop配置conf/hive-site.xml(hive-site.xml的优先级高于hive-default.xml的优先级,两者共有的字段只有hive-site.xml中的配置生效)
复制hive-default.xml.template为hive-site.xml,在configuration中最后添加两个property
1
2
3
4
5
6
7
8
9
10
<property>
<name>system:java.io.tmpdir</name>
<value>/mnt/home/1015146591/apps/hive-1.2.2/tmp</value>
</property>
<property>
<name>system:user.name</name>
<value>1015146591</value>
</property>另外修改一下hive-site.xml中hive.metastore.warehouse.dir的值,这个值表示回头你创建的数据库在HDFS上的存放位置:
1
2
3
4
5<property>
<name>hive.metastore.warehouse.dir</name>
<value>1015146591/warehouse</value>
<description>location of default database for the warehouse</description>
</property>启动hive(z在hive目录下启动)
1
./bin/hive
1
2
3
4hive> show databases;
OK
default
Time taken: 1.293 seconds, Fetched: 1 row(s)
创建和管理Hive中的数据
Hive中创建数据库
最简单的创建数据库方法:
1
2
3
4
5
6
7
8hive> create database bigdata;
OK
Time taken: 0.065 seconds
hive> show databases;
OK
bigdata
default
Time taken: 0.01 seconds, Fetched: 2 row(s)重复创建数据库会报错:
1
2hive> create database bigdata;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database bigdata already exists更严谨的做法是:
1
2
3
4hive> create database if not exists bigdata;
OK
Time taken: 0.013 seconds
`删除一个数据库
1
2
3
4
5
6
7hive> drop database if exists bigdata;
OK
Time taken: 0.327 seconds
hive> show databases;
OK
default
Time taken: 0.018 seconds, Fetched: 1 row(s)创建外部表
拷贝json解析包到hive目录下的lib
1
cp /tmp/hivecourse/json-serde-1.3.6-jar-with-dependencies.jar /mnt/home/1015146591/apps/hive-1.2.2/lib
在Hive文件中增加该jar包配置
1
2
3
4<property>
<name>hive.aux.jars.path</name>
<value>file:///mnt/home/1015146591/apps/hive-1.2.2/lib/json-serde-1.3.6-jar-with-dependencies.jar</value>
</property>创建Hive数据表,建表语句如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22CREATE EXTERNAL TABLE IF NOT EXISTS `bigdata.weblog` (
`time_tag` bigint COMMENT '时间',
`active_name` string COMMENT '事件名称',
`device_id` string COMMENT '设备id',
`session_id` string COMMENT '会话id',
`user_id` string COMMENT '用户id',
`ip` string COMMENT 'ip地址',
`address` map<string, string> COMMENT '地址',
`req_url` string COMMENT 'http请求地址',
`action_path` array<string> COMMENT '访问路径',
`product_id` string COMMENT '商品id',
`order_id` string COMMENT '订单id'
) PARTITIONED BY(
`day` string COMMENT '日期'
) ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/hadoop/weblog';添加分区指令
1
2
3
4
5
6
7
8
9
10alter table bigdata.weblog add partition (day='2018-05-29') location '/user/hadoop/weblog/day=2018-05-29';
alter table bigdata.weblog add partition (day='2018-05-30') location '/user/hadoop/weblog/day=2018-05-30';
alter table bigdata.weblog add partition (day='2018-05-31') location '/user/hadoop/weblog/day=2018-05-31';
alter table bigdata.weblog add partition (day='2018-06-01') location '/user/hadoop/weblog/day=2018-06-01';
alter table bigdata.weblog add partition (day='2018-06-02') location '/user/hadoop/weblog/day=2018-06-02';
alter table bigdata.weblog add partition (day='2018-06-03') location '/user/hadoop/weblog/day=2018-06-03';
alter table bigdata.weblog add partition (day='2018-06-04') location '/user/hadoop/weblog/day=2018-06-04';
alter table bigdata.weblog add partition (day='2018-06-05') location '/user/hadoop/weblog/day=2018-06-05';
alter table bigdata.weblog add partition (day='2018-06-06') location '/user/hadoop/weblog/day=2018-06-06';
alter table bigdata.weblog add partition (day='2018-06-07') location '/user/hadoop/weblog/day=2018-06-07';
配置hive使用mysql存储元数据
修改hive-site.xml,将下面的内容:
1 | <!--JDBC元数据仓库连接字符串--> |
替换成下面的内容,需要提前将mysql的驱动下载并放到hive的lib目录下:
1 | <property> |
根据实际情况填写mysql的ip,然后运行hive即可。
写一个基本的查询语句
SELECT的用法
用户(user_id)访问了什么网页(req_url)?
1
select time_tag, user_id, req_url from bigdata.weblog limit 10;
查询结果:
1
2
3
4
5
6
7
8
9
10
11
12
13hive> select time_tag, user_id, req_url from bigdata.weblog limit 10;
OK
1527604188966 4921528165744221 http://www.bigdataclass.com/category
1527604410990 4921528165744221 http://www.bigdataclass.com
1527604638195 4921528165744221 http://www.bigdataclass.com
1527604714462 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527604879475 4921528165744221 http://www.bigdataclass.com/category
1527604964330 4921528165744221 http://www.bigdataclass.com/category
1527605154014 4921528165744221 http://www.bigdataclass.com/category
1527605190626 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527605398767 4921528165744221 http://www.bigdataclass.com/product/1527235438747116
1527605466969 4921528165744221 http://www.bigdataclass.com/product/1527235438747157
Time taken: 0.062 seconds, Fetched: 10 row(s)
WHERE的用法
用户(user_id=xxx)访问了什么网页(req_url)?
1
select time_tag, user_id, req_url from bigdata.weblog where user_id='4921528165744221' and day='2018-05-29';
查询结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35hive> select time_tag, user_id, req_url from bigdata.weblog where user_id='4921528165744221' and day='2018-05-29';
OK
1527604188966 4921528165744221 http://www.bigdataclass.com/category
1527604410990 4921528165744221 http://www.bigdataclass.com
1527604638195 4921528165744221 http://www.bigdataclass.com
1527604714462 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527604879475 4921528165744221 http://www.bigdataclass.com/category
1527604964330 4921528165744221 http://www.bigdataclass.com/category
1527605154014 4921528165744221 http://www.bigdataclass.com/category
1527605190626 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527605398767 4921528165744221 http://www.bigdataclass.com/product/1527235438747116
1527605466969 4921528165744221 http://www.bigdataclass.com/product/1527235438747157
1527605536435 4921528165744221 http://www.bigdataclass.com/product/1527235438748068
1527605740447 4921528165744221 http://www.bigdataclass.com/category
1527594315438 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527594532642 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527594630140 4921528165744221 http://www.bigdataclass.com
1527594739145 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527594794926 4921528165744221 http://www.bigdataclass.com/category
1527594987391 4921528165744221 http://www.bigdataclass.com
1527595196976 4921528165744221 http://www.bigdataclass.com/category
1527595391276 4921528165744221 http://www.bigdataclass.com
1527595503065 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527595691945 4921528165744221 http://www.bigdataclass.com/product/1527235438748291
1527595920306 4921528165744221 http://www.bigdataclass.com/product/1527235438747370
1527596123417 4921528165744221 http://www.bigdataclass.com/category
1527596236662 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
1527596475796 4921528165744221 http://www.bigdataclass.com/product/1527235438748068
1527596643269 4921528165744221 http://www.bigdataclass.com/product/1527235438749679
1527596673093 4921528165744221 http://www.bigdataclass.com
1527596857131 4921528165744221 http://www.bigdataclass.com
1527596882285 4921528165744221 http://www.bigdataclass.com/product/1527235438748572
1527597101997 4921528165744221 http://www.bigdataclass.com/product/1527235438746733
1527597158210 4921528165744221 http://www.bigdataclass.com/my/4921528165744221
Time taken: 0.231 seconds, Fetched: 32 row(s)
子查询和关联表
关联表JOIN
下单用户是谁?如果获取更多信息
创建一个用户表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16CREATE EXTERNAL TABLE IF NOT EXISTS `bigdata.member` (
`user_id` string COMMENT '用户id',
`nick_name` string COMMENT '昵称',
`name` string COMMENT '姓名',
`gender` string COMMENT '性别',
`register_time` bigint COMMENT '注册时间',
`birthday` bigint COMMENT '生日',
`device_type` string COMMENT '设备类型')
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/hadoop/hive/member';执行结果:
1
2
3
4
5
6
7
8
9
10hive> desc member;
OK
user_id string 用户id
nick_name string 昵称
name string 姓名
gender string 性别
register_time bigint 注册时间
birthday bigint 生日
device_type string 设备类型
Time taken: 0.05 seconds, Fetched: 7 row(s)关联用户表信息:
1
2
3
4
5
6
7
8
9
10select
t1.user_id,
gender,
register_time
from
(select user_id from bigdata.weblog where active_name='order') t1
join
(select user_id, gender, register_time from bigdata.member) t2
on t1.user_id=t2.user_id
limit 10;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51hive> select
> t1.user_id,
> gender,
> register_time
> from
> (select user_id from bigdata.weblog where active_name='order') t1
> join
> (select user_id, gender, register_time from bigdata.member) t2
> on t1.user_id=t2.user_id limit 10;
Query ID = 1015146591_20190106140901_6897753b-2c29-4c81-9aaa-c03876e46e1e
Total jobs = 1
Execution log at: /tmp/1015146591/1015146591_20190106140901_6897753b-2c29-4c81-9aaa-c03876e46e1e.log
2019-01-06 14:09:05 Starting to launch local task to process map join; maximum memory = 508559360
2019-01-06 14:09:06 Dump the side-table for tag: 1 with group count: 30179 into file: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/56a2b2ad-eab4-4e0a-a49d-f0bfd62e96fc/hive_2019-01-06_14-09-01_666_424795490568777106-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile11--.hashtable
2019-01-06 14:09:06 Uploaded 1 File to: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/56a2b2ad-eab4-4e0a-a49d-f0bfd62e96fc/hive_2019-01-06_14-09-01_666_424795490568777106-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile11--.hashtable (1395272 bytes)
2019-01-06 14:09:06 End of local task; Time Taken: 1.491 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1535253853575_21356, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21356/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21356
Hadoop job information for Stage-3: number of mappers: 6; number of reducers: 0
2019-01-06 14:09:13,778 Stage-3 map = 0%, reduce = 0%
2019-01-06 14:09:21,078 Stage-3 map = 33%, reduce = 0%, Cumulative CPU 8.53 sec
2019-01-06 14:09:23,137 Stage-3 map = 50%, reduce = 0%, Cumulative CPU 16.27 sec
2019-01-06 14:09:25,224 Stage-3 map = 54%, reduce = 0%, Cumulative CPU 48.62 sec
2019-01-06 14:09:28,319 Stage-3 map = 69%, reduce = 0%, Cumulative CPU 58.85 sec
2019-01-06 14:09:30,379 Stage-3 map = 77%, reduce = 0%, Cumulative CPU 62.09 sec
2019-01-06 14:09:31,412 Stage-3 map = 78%, reduce = 0%, Cumulative CPU 68.57 sec
2019-01-06 14:09:32,465 Stage-3 map = 86%, reduce = 0%, Cumulative CPU 69.58 sec
2019-01-06 14:09:34,543 Stage-3 map = 93%, reduce = 0%, Cumulative CPU 75.94 sec
2019-01-06 14:09:36,615 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 78.36 sec
MapReduce Total cumulative CPU time: 1 minutes 18 seconds 360 msec
Ended Job = job_1535253853575_21356
MapReduce Jobs Launched:
Stage-Stage-3: Map: 6 Cumulative CPU: 78.36 sec HDFS Read: 942484283 HDFS Write: 760 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 18 seconds 360 msec
OK
8201531897436759 男 1526031234916
2211531897362630 男 1519311748534
8431531897389241 男 1520079723099
3211531897369709 男 1523560308175
6911531897308202 女 1525233502748
5041531897225960 男 1527678449938
7391531897436409 女 1527670790734
8191531897363226 男 1526696249998
0851531897431904 女 1524085244386
7031531897150536 女 1527243924519
Time taken: 36.225 seconds, Fetched: 10 row(s)
hive>
总结
1 | select |
这里t1、t2是子查询的别名,两个子查询语句通过公共字段进行关联。
join分四种情况

使用简单函数
Hive函数分类
内置函数:hive自带的函数
简单函数:一进一出,用于格式化、数据运算等
聚合函数:多进一出,用于统计计算、指标聚合等
集合函数:array、map操作
特殊函数:窗口函数等
自定义函数
简单函数
时间戳转换函数from_unixtime()
前一节获取的数据t1.user_id, gender, register_time,其中register_time是时间戳格式,方便给机器读,但是不利于人阅读。
1
2
3
4
5
6
7
8
9select
t1.user_id,
gender,
from_unixtime(cast(register_time/1000 as bigint), 'yyyy-MM-dd HH:mm:ss') as register_day
from
(select user_id from bigdata.weblog where active_name='order') t1
join
(select user_id, gender, register_time from bigdata.member) t2
on t1.user_id=t2.user_id limit 10;运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51hive> select
> t1.user_id,
> gender,
> from_unixtime(cast(register_time/1000 as bigint), 'yyyy-MM-dd HH:mm:ss') as register_day
> from
> (select user_id from bigdata.weblog where active_name='order') t1
> join
> (select user_id, gender, register_time from bigdata.member) t2
> on t1.user_id=t2.user_id limit 10;
Query ID = 1015146591_20190106145912_357aaca8-c7cf-4573-b078-f8656f24c59d
Total jobs = 1
Execution log at: /tmp/1015146591/1015146591_20190106145912_357aaca8-c7cf-4573-b078-f8656f24c59d.log
2019-01-06 14:59:16 Starting to launch local task to process map join; maximum memory = 508559360
2019-01-06 14:59:19 Dump the side-table for tag: 1 with group count: 30179 into file: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/56a2b2ad-eab4-4e0a-a49d-f0bfd62e96fc/hive_2019-01-06_14-59-12_260_600547876088340954-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable
2019-01-06 14:59:19 Uploaded 1 File to: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/56a2b2ad-eab4-4e0a-a49d-f0bfd62e96fc/hive_2019-01-06_14-59-12_260_600547876088340954-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable (1395272 bytes)
2019-01-06 14:59:19 End of local task; Time Taken: 2.183 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1535253853575_21357, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21357/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21357
Hadoop job information for Stage-3: number of mappers: 6; number of reducers: 0
2019-01-06 14:59:28,200 Stage-3 map = 0%, reduce = 0%
2019-01-06 14:59:33,542 Stage-3 map = 33%, reduce = 0%, Cumulative CPU 9.1 sec
2019-01-06 14:59:35,690 Stage-3 map = 50%, reduce = 0%, Cumulative CPU 16.09 sec
2019-01-06 14:59:37,769 Stage-3 map = 51%, reduce = 0%, Cumulative CPU 27.57 sec
2019-01-06 14:59:38,796 Stage-3 map = 54%, reduce = 0%, Cumulative CPU 49.7 sec
2019-01-06 14:59:40,912 Stage-3 map = 61%, reduce = 0%, Cumulative CPU 53.04 sec
2019-01-06 14:59:41,946 Stage-3 map = 69%, reduce = 0%, Cumulative CPU 59.86 sec
2019-01-06 14:59:43,998 Stage-3 map = 78%, reduce = 0%, Cumulative CPU 66.35 sec
2019-01-06 14:59:46,161 Stage-3 map = 86%, reduce = 0%, Cumulative CPU 70.27 sec
2019-01-06 14:59:47,187 Stage-3 map = 93%, reduce = 0%, Cumulative CPU 76.48 sec
2019-01-06 14:59:50,264 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 78.99 sec
MapReduce Total cumulative CPU time: 1 minutes 18 seconds 990 msec
Ended Job = job_1535253853575_21357
MapReduce Jobs Launched:
Stage-Stage-3: Map: 6 Cumulative CPU: 78.99 sec HDFS Read: 942488681 HDFS Write: 880 SUCCESS
Total MapReduce CPU Time Spent: 1 minutes 18 seconds 990 msec
OK
8201531897436759 男 2018-05-11 17:33:54
2211531897362630 男 2018-02-22 23:02:28
8431531897389241 男 2018-03-03 20:22:03
3211531897369709 男 2018-04-13 03:11:48
6911531897308202 女 2018-05-02 11:58:22
5041531897225960 男 2018-05-30 19:07:29
7391531897436409 女 2018-05-30 16:59:50
8191531897363226 男 2018-05-19 10:17:29
0851531897431904 女 2018-04-19 05:00:44
7031531897150536 女 2018-05-25 18:25:24
Time taken: 39.182 seconds, Fetched: 10 row(s)日期函数:from_unixtime, unit_timestamp, to_date, date_diff ……
字符串函数:concat, concat_ws, format_number, upper/lower, parse_url ……
条件函数:if, case……when……
数学函数:round/ceil/floor, log, power, rand……
Hive自带函数
查看Hive自带函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219hive> show functions;
OK
!
!=
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
abs
acos
add_months
and
array
array_contains
ascii
asin
assert_true
atan
avg
base64
between
bin
case
cbrt
ceil
ceiling
coalesce
collect_list
collect_set
compute_stats
concat
concat_ws
context_ngrams
conv
corr
cos
count
covar_pop
covar_samp
create_union
cume_dist
current_database
current_date
current_timestamp
current_user
date_add
date_format
date_sub
datediff
day
dayofmonth
decode
degrees
dense_rank
div
e
elt
encode
ewah_bitmap
ewah_bitmap_and
ewah_bitmap_empty
ewah_bitmap_or
exp
explode
factorial
field
find_in_set
first_value
floor
format_number
from_unixtime
from_utc_timestamp
get_json_object
greatest
hash
hex
histogram_numeric
hour
if
in
in_file
index
initcap
inline
instr
isnotnull
isnull
java_method
json_tuple
lag
last_day
last_value
lcase
lead
least
length
levenshtein
like
ln
locate
log
log10
log2
lower
lpad
ltrim
map
map_keys
map_values
matchpath
max
min
minute
month
months_between
named_struct
negative
next_day
ngrams
noop
noopstreaming
noopwithmap
noopwithmapstreaming
not
ntile
nvl
or
parse_url
parse_url_tuple
percent_rank
percentile
percentile_approx
pi
pmod
posexplode
positive
pow
power
printf
radians
rand
rank
reflect
reflect2
regexp
regexp_extract
regexp_replace
repeat
reverse
rlike
round
row_number
rpad
rtrim
second
sentences
shiftleft
shiftright
shiftrightunsigned
sign
sin
size
sort_array
soundex
space
split
sqrt
stack
std
stddev
stddev_pop
stddev_samp
str_to_map
struct
substr
substring
sum
tan
to_date
to_unix_timestamp
to_utc_timestamp
translate
trim
trunc
ucase
unbase64
unhex
unix_timestamp
upper
var_pop
var_samp
variance
weekofyear
when
windowingtablefunction
xpath
xpath_boolean
xpath_double
xpath_float
xpath_int
xpath_long
xpath_number
xpath_short
xpath_string
year
|
~
Time taken: 0.009 seconds, Fetched: 216 row(s)查看函数具体用法:
1
2
3
4hive> describe function weekofyear;
OK
weekofyear(date) - Returns the week of the year of the given date. A week is considered to start on a Monday and week 1 is the first week with >3 days.
Time taken: 0.011 seconds, Fetched: 1 row(s)
使用聚合函数
Hive函数分类
内置函数:hive自带的函数
简单函数:一进一出,用于格式化、数据运算等
聚合函数:多进一出,用于统计计算、指标聚合等
集合函数:array、map操作
特殊函数:窗口函数等
自定义函数
聚合函数
商品详情页被访问了多少次?
这里不关心是哪些用户(user_id)在什么时间(timt_tag)访问了什么内容(req_url),这里比较关心的是有多少用户访问了a商品,有多少用户访问了b商品。
明细数据包含的内容比较全面和细致,有时候我们不需要所有的信息,而是需要在详细信息的基础上抽象统计出一些信息,也就是汇总级别的统计数据,这就需要借助聚合函数来完成。
使用sql来统计商品详情页面被访问了多少次:
1
2
3
4
5
6
7
8
9
10
11
12select
req_url,
count(1)
from
bigdata.weblog
where
active_name='pageview'
and
req_url like '%/product/%'
group by
req_url
limit 10;Hive执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55hive> select
> req_url,
> count(1)
> from
> bigdata.weblog
> where
> active_name='pageview'
> and
> req_url like '%/product/%'
> group by
> req_url
> limit 10;
Query ID = 1015146591_20190108134436_e79d8a13-03f7-4c63-9018-e90ae7b5ff44
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 7
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535253853575_21652, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21652/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21652
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 7
2019-01-08 13:44:42,854 Stage-1 map = 0%, reduce = 0%
2019-01-08 13:44:51,233 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 6.4 sec
2019-01-08 13:44:53,292 Stage-1 map = 18%, reduce = 0%, Cumulative CPU 27.05 sec
2019-01-08 13:44:54,324 Stage-1 map = 20%, reduce = 0%, Cumulative CPU 58.09 sec
2019-01-08 13:44:56,402 Stage-1 map = 31%, reduce = 0%, Cumulative CPU 67.98 sec
2019-01-08 13:44:57,442 Stage-1 map = 36%, reduce = 0%, Cumulative CPU 74.22 sec
2019-01-08 13:44:59,514 Stage-1 map = 48%, reduce = 0%, Cumulative CPU 87.63 sec
2019-01-08 13:45:01,688 Stage-1 map = 59%, reduce = 2%, Cumulative CPU 94.16 sec
2019-01-08 13:45:02,716 Stage-1 map = 70%, reduce = 6%, Cumulative CPU 106.81 sec
2019-01-08 13:45:03,742 Stage-1 map = 90%, reduce = 6%, Cumulative CPU 108.65 sec
2019-01-08 13:45:04,771 Stage-1 map = 100%, reduce = 14%, Cumulative CPU 111.35 sec
2019-01-08 13:45:05,798 Stage-1 map = 100%, reduce = 44%, Cumulative CPU 116.75 sec
2019-01-08 13:45:06,867 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 128.85 sec
MapReduce Total cumulative CPU time: 2 minutes 8 seconds 850 msec
Ended Job = job_1535253853575_21652
MapReduce Jobs Launched:
Stage-Stage-1: Map: 6 Reduce: 7 Cumulative CPU: 128.85 sec HDFS Read: 1571454468 HDFS Write: 3828 SUCCESS
Total MapReduce CPU Time Spent: 2 minutes 8 seconds 850 msec
OK
http://www.bigdataclass.com/product/1527235438746948 6582
http://www.bigdataclass.com/product/1527235438747116 6646
http://www.bigdataclass.com/product/1527235438747270 6510
http://www.bigdataclass.com/product/1527235438748068 6562
http://www.bigdataclass.com/product/1527235438748572 6495
http://www.bigdataclass.com/product/1527235438748621 6535
http://www.bigdataclass.com/product/1527235438748929 6482
http://www.bigdataclass.com/product/1527235438750182 6545
http://www.bigdataclass.com/product/1527235438751036 6489
http://www.bigdataclass.com/product/1527235438751281 6564
Time taken: 31.223 seconds, Fetched: 10 row(s)男女用户谁更会花钱?
统计男女用户哪一类人群下单金额更多,sql语句如下:
1
2
3
4
5
6
7
8
9
10
11
12select
gender,
count(t1.user_id) as count_order,
sum(pay_amount) as sum_amount,
avg(pay_amount) as avg_amount
from
(select user_id, pay_amount from bigdata.orders) t1
join
(select user_id, gender from bigdata.member) t2
on t1.user_id=t2.user_id
group by
gender建立订单表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15create external table `bigdata.orders` (
`order_id` string comment '订单id',
`user_id` string comment '用户id',
`product_id` string comment '商品id',
`order_time` bigint comment '下单时间',
`pay_amount` double comment '金额'
)
row format SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/hadoop/hive/orders'创建结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26hive> create external table `bigdata.orders` (
> `order_id` string comment '订单id',
> `user_id` string comment '用户id',
> `product_id` string comment '商品id',
> `order_time` bigint comment '下单时间',
> `pay_amount` double comment '金额'
> )
> row format SERDE
> 'org.openx.data.jsonserde.JsonSerDe'
> STORED AS INPUTFORMAT
> 'org.apache.hadoop.mapred.TextInputFormat'
> OUTPUTFORMAT
> 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
> LOCATION
> '/user/hadoop/hive/orders';
OK
Time taken: 0.076 seconds
hive> desc orders;
OK
order_id string 订单id
user_id string 用户id
product_id string 商品id
order_time bigint 下单时间
pay_amount double 金额
Time taken: 0.34 seconds, Fetched: 5 row(s)统计男女用户哪一类人群下单金额更多执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44hive> select
> gender,
> count(t1.user_id) as count_order,
> sum(pay_amount) as sum_amount,
> avg(pay_amount) as avg_amount
> from
> (select user_id, pay_amount from bigdata.orders) t1
> join
> (select user_id, gender from bigdata.member) t2
> on t1.user_id=t2.user_id
> group by
> gender;
Query ID = 1015146591_20190106193552_f6a32384-3cdd-4343-a22a-5394c7a8b072
Total jobs = 1
Execution log at: /tmp/1015146591/1015146591_20190106193552_f6a32384-3cdd-4343-a22a-5394c7a8b072.log
2019-01-06 19:35:56 Starting to launch local task to process map join; maximum memory = 508559360
2019-01-06 19:35:58 Dump the side-table for tag: 0 with group count: 15104 into file: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/4195d5ac-cd0c-484a-ad5a-8a74a78d0bf6/hive_2019-01-06_19-35-52_975_5737141907165469961-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile00--.hashtable
2019-01-06 19:35:58 Uploaded 1 File to: file:/mnt/home/1015146591/apps/hive-1.2.2/tmp/1015146591/4195d5ac-cd0c-484a-ad5a-8a74a78d0bf6/hive_2019-01-06_19-35-52_975_5737141907165469961-1/-local-10004/HashTable-Stage-2/MapJoin-mapfile00--.hashtable (652905 bytes)
2019-01-06 19:35:58 End of local task; Time Taken: 1.317 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535253853575_21374, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21374/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21374
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2019-01-06 19:36:06,133 Stage-2 map = 0%, reduce = 0%
2019-01-06 19:36:12,393 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 4.96 sec
2019-01-06 19:36:18,670 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 7.37 sec
MapReduce Total cumulative CPU time: 7 seconds 370 msec
Ended Job = job_1535253853575_21374
MapReduce Jobs Launched:
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 7.37 sec HDFS Read: 4829952 HDFS Write: 78 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 370 msec
OK
女 7635 474593.0 62.16018336607728
男 7469 464502.0 62.19065470611862
Time taken: 26.789 seconds, Fetched: 2 row(s)
利用正则表达精确提取信息
原始日志数据的局限
特定业务数据,往往只针对特定业务场景埋点。
如何获取商品的访问量
日志详情中只有下单后才会记录商品id,这就需要从其他表中提取出相关信息然后组合得到商品的访问量。数据匹配和提取一般使用正则表达式。
正则表达式
正则表达式描述了一种字符串匹配的模式,可以用来:
检查一个字符串是否含有某种字串
将匹配的字串替换
从某个字符串中去除符合某个条件的字串
Hive中对应的的正则表达式函数
regexp: A regexp ‘[0-9]+’
regexp_replace: regexp_replace(A, ‘[0-9]+’, ‘’)
regexp_extract: regexp_extract(A, ‘([0-9]+)’, 1)
这里有我之前写的正则表达式基础,介绍了正则表达式常用的功能,可以参考一下。
计算商品访问量
用户访问的url类似下面这种:
1 | http://www.bigdataclass.com/my/4921528165744221 |
这里面其实包含有商品id:4921528165744221,也就是可以从url中提取商品id。
从日志表中提取商品req_url的sql查询语句如下:
1 | select |
执行结果:
1 | hive> select |
使用窗口函数
窗口函数
如果存在多行输入,多行输出,并且要求输出的每行数据不仅包含它所在行的数据信息,还包括它所在分组内的其他行的信息,这时就需要窗口函数完成。
下单用户路径分析

有时我们不仅想知道用户当前的行为,还想知道用户当前行为前后用户的行为轨迹:
从哪个页面着陆? ——> 窗口内排序或偏移量
下单前的最后页面? ——> 窗口内偏移量
下单之前浏览了多少页面? ——> 窗口内聚合
窗口函数的语法
- 语法格式:
1 | Function(arg1, ....argn) OVER ([PARTITION BY<...>] [ORDER BY<...>] [window_clause]) |
偏移量函数
First_value/Last_value
Lead/Lag
聚合函数
COUNT/SUM
AVG/MIN/MAX
排序函数
ROW_NUMBER()
RNAK()
DENSE_RANK()
实际操作
1 | select |
这里的count_visit中添加了row between关键字用于指定窗口范围,默认是从开始到当前行。使用partition by进行分组,count_visit表示下单前浏览了多少个页面,last_page表示下单前浏览的最后一个页面,landing_page表示该用户从哪个页面开始浏览的。
运行结果:
1 | hive> select |
行转列与列转行
行转列业务场景
业务场景:用户分析
要做用户分析,但是原始数据中及记录的是每条日志详情,内容如下:
| 用户id | 购买商品id |
|---|---|
| 001 | Product1 |
| 001 | Product1 |
| 001 | Product1 |
| 001 | Product1 |
| 001 | Product1 |
| 001 | Product1 |
| ….. | ….. |
这个粒度太细,不便于我们分析,我们其实想得到的可能是用户维度的数据,类似下面这种:
| 用户id | 购买商品id |
|---|---|
| 001 | Product1, Product2, product3 |
| 002 | Product1, Product2, product3 |
| … | … |
也就是把它聚合成每个用户为一行,把一个用户购买的所有商品都聚合到一个字段中,这其实就是行转列的操作。
Hive中行转列函数
collect_set(): 不插入重复记录
collect_list(): 保留重复记录
SQL测试语句:
1 | select |
测试结果:
1 | hive> select |
使用这两个行专列的函数类似于下表所示:
| 用户id | 购买商品id(collect_set) | 购买商品id(collect_list) |
|---|---|---|
| 0001 | product1, product2 | product1, product2, product2 |
| 0002 | product1, product2, product3 | product1, product2, product3 |
| … | … | … |
collect_set和collect_list就是聚合函数的一种,这里单独列出来讲是因为在实际业务中经常使用行转列和列转行这两种方法。
用户画像
用户画像是指根据用户的社会属性、生活习惯、消费行为等等各种信息抽象出来的一个标签化的用户模型,用户画像的作用是让用户的运营更加精细化,根据用户特点去做不同的运营措施。
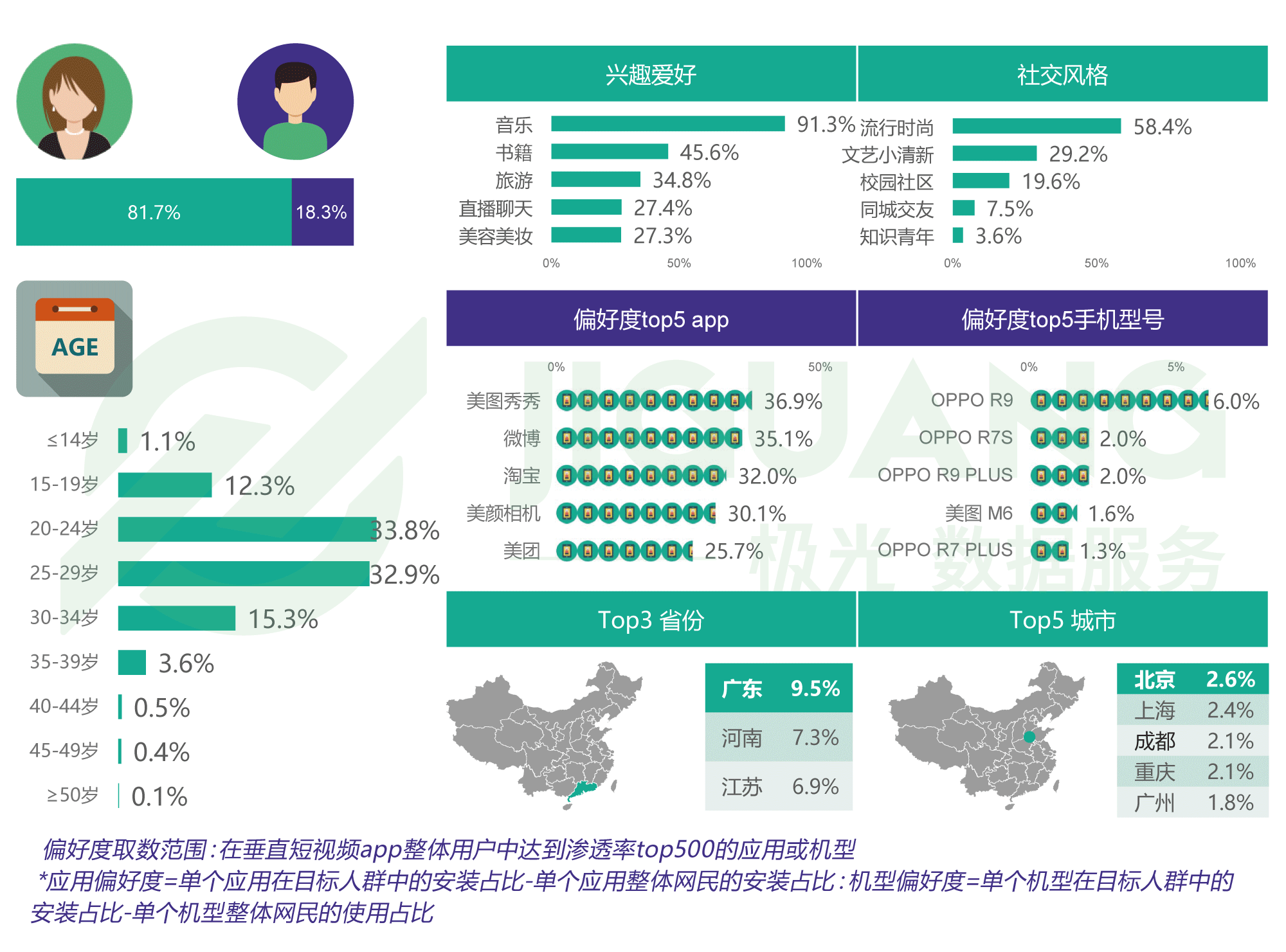
用户画像的核心就是对用户打标签,比如可以从业务数据中整理出下列用户信息:
性别
年龄
设备类型
注册时间
首次下单时间
最近一次下单时间
下单次数
下单金额
最近一次下单地理位置
…
根据这一系列数据就可以建立起一个庞大的用户画像标签库,基于这个标签库可以分析用户相关的各种行为,从而针对不同的用户指定不同的运营策略。
现在有一个问题:建立这些标签的数据往往是分布在不同的日志数据源中的,应该通过怎样的一种方式来建立用户画像标签库呢?
计算N个指标的实现方式一
通过一个个子语句从不同的数据表中加工出需要的数据指标,然后通过庞大的sql把这些指标串联起来,这是最直接的方式,往往也是最麻烦的方式。
sql语句大概是这个样子:
1 | select |
这种方法的优点:直观
缺点:
代码冗长
字段输出顺序固定,可维护性弱
运行效率低下:所有指标都集中在一个sql语句中,不能并行执行,导致效率低下。
计算N个指标的实现方式二
使用行转列或列转行的方式来完成用户标签库的建立,把一步实现的方式分多步完成,一般步骤如下:
建立key-value中间表
分组计算各字段,列转行存入中间表
中间表行转列为大宽表
先建一个中间表和一个大宽表:
中间表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14create external table `bigdata.user_tag_value` (
`user_id` string comment '用户组',
`tag` string comment '标签',
`value` string comment '标签值')
partitioned by (
`module` string comment '标签模块')
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location
'/user/1015146591/hive/user_profile/tag_value'大宽表:
1
2
3
4
5
6
7
8
9
10
11create external table `bigdata.user_profile` (
`user_id` string comment '用户id',
`profile` string comment '用户标签')
row format serde
'org.openx.data.jsonserde.JsonSerDe'
stored as inputformat
'org.apache.hadoop.mapred.TextInputFormat'
outputformat
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location
'/user/1015146591/hive/user_profile/user_profile'分别执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31hive>
>
> create external table `bigdata.user_tag_value` (
> `user_id` string comment '用户组',
> `tag` string comment '标签',
> `value` string comment '标签值')
> partitioned by (
> `module` string comment '标签模块')
> ROW FORMAT SERDE
> 'org.openx.data.jsonserde.JsonSerDe'
> STORED AS INPUTFORMAT
> 'org.apache.hadoop.mapred.TextInputFormat'
> OUTPUTFORMAT
> 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
> location
> '/user/1015146591/hive/user_profile/tag_value';
OK
Time taken: 0.195 seconds
hive> create external table `bigdata.user_profile` (
> `user_id` string comment '用户id',
> `profile` string comment '用户标签')
> row format serde
> 'org.openx.data.jsonserde.JsonSerDe'
> stored as inputformat
> 'org.apache.hadoop.mapred.TextInputFormat'
> outputformat
> 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
> location
> '/user/1015146591/hive/user_profile/user_profile';
OK
Time taken: 0.041 seconds然后计算各个字段,存入中间表,先分组group1,将用户的性别、年龄、设备类型、注册日期提取出来存放到中间表中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17insert overwrite table bigdata.user_tag_value partition(module='basic_info')
select
user_id,
mp['key'],
mp['value']
from
(select
user_id,
array(
map('key', 'gender', 'value', gender),
map('key', 'age', 'value', cast(2018-from_unixtime(cast(birthday/1000 as bigint), 'yyyy') as string)),
map('key', 'device_type', 'value', device_type),
map('key', 'register_day', 'value', from_unixtime(cast(register_time/1000 as bigint), 'yyyy-MM-dd'))
) as arr
from
bigdata.member
) s lateral view explode(arr) arrtable as mp执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37hive> insert overwrite table bigdata.user_tag_value partition(module='basic_info')
> select
> user_id,
> mp['key'],
> mp['value']
> from
> (select
> user_id,
> array(map('key', 'gender', 'value', gender),
> map('key', 'age', 'value', cast(2018-from_unixtime(cast(birthday/1000 as bigint) , 'yyyy') as string)),
> map('key', 'device_type', 'value', device_type),
> map('key', 'register_day', 'value', from_unixtime(cast(register_time/1000 as big int), 'yyyy-MM-dd'))
> ) as arr
> from
> bigdata.member) s lateral view explode(arr) arrtable as mp;
Query ID = 1015146591_20190107223740_dc7872a5-d395-4673-815d-1db820668c96
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1535253853575_21572, Tracking URL = http://bigdata0.novalocal:8088/prox y/application_1535253853575_21572/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21572
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2019-01-07 22:37:46,508 Stage-1 map = 0%, reduce = 0%
2019-01-07 22:37:53,799 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.17 sec
MapReduce Total cumulative CPU time: 7 seconds 170 msec
Ended Job = job_1535253853575_21572
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://bigdata0:50000/user/1015146591/hive/user_profile/tag_value/module=basic_info/.hive-staging_hive_2019-01-07_22-37-40_449_2087025953513902676-1/-ext-10000
Loading data to table bigdata.user_tag_value partition (module=basic_info)
Partition bigdata.user_tag_value{module=basic_info} stats: [numFiles=1, numRows=120716, totalSize=7796231, rawDataSize=0]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 7.17 sec HDFS Read: 4822507 HDFS Write: 7796331 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 170 msec
OK
Time taken: 14.745 seconds查看一下执行后中间表内的数据:
1
select * from bigdata.user_tag_value limit 10;
1
2
3
4
5
6
7
8
9
10
11
12
13hive> select * from bigdata.user_tag_value limit 10;
OK
0001528166058390 gender 女 basic_info
0001528166058390 age 26.0 basic_info
0001528166058390 device_type WEB basic_info
0001528166058390 register_day 2018-04-09 basic_info
0001531897045258 gender 男 basic_info
0001531897045258 age 34.0 basic_info
0001531897045258 device_type IPhone basic_info
0001531897045258 register_day 2018-03-26 basic_info
0001531897084097 gender 女 basic_info
0001531897084097 age 39.0 basic_info
Time taken: 0.101 seconds, Fetched: 10 row(s)提取首次下单时间、最近下单时间、下单次数、下单金额
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19insert overwrite table bigdata.user_tag_value partition(module='consume_info')
select
user_id,
mp['key'],
mp['value']
from
(select
user_id,
array(
map('key', 'first_order_time', 'value', min(order_time)),
map('key', 'last_order_time', 'value', max(order_time)),
map('key', 'order_count', 'value', count(1)),
map('key', 'order_sum', 'value', sum(pay_amount))
) as arr
from
bigdata.orders
group by
user_id
) s lateral view explode(arr) arrtable as mp执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44hive> insert overwrite table bigdata.user_tag_value partition(module='consume_info')
> select
> user_id,
> mp['key'],
> mp['value']
> from
> (select
> user_id,
> array(
> map('key', 'first_order_time', 'value', min(order_time)),
> map('key', 'last_order_time', 'value', max(order_time)),
> map('key', 'order_count', 'value', count(1)),
> map('key', 'order_sum', 'value', sum(pay_amount))
> ) as arr
> from
> bigdata.orders
> group by
> user_id
> ) s lateral view explode(arr) arrtable as mp;
Query ID = 1015146591_20190107225440_13303ef4-cfc3-4eae-bb89-42f04e10689e
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535253853575_21573, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21573/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21573
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-01-07 22:54:47,927 Stage-1 map = 0%, reduce = 0%
2019-01-07 22:54:53,307 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.77 sec
2019-01-07 22:54:59,521 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 9.63 sec
MapReduce Total cumulative CPU time: 9 seconds 630 msec
Ended Job = job_1535253853575_21573
Loading data to table bigdata.user_tag_value partition (module=consume_info)
Partition bigdata.user_tag_value{module=consume_info} stats: [numFiles=1, numRows=60416, totalSize=4321419, rawDataSize=0]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 9.63 sec HDFS Read: 2068108 HDFS Write: 4321520 SUCCESS
Total MapReduce CPU Time Spent: 9 seconds 630 msec
OK
Time taken: 19.868 seconds最后一组中间表指标,包含地理位置信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16insert overwrite table bigdata.user_tag_value partition(module='geography_info')
select
user_id,
'province' as key,
province
from
(select
user_id,
row_number() over (partition by user_id order by time_tag desc) as order_rank,
address['province'] as province
from
bigdata.weblog
where
active_name = 'pay') t1
where
order_rank = 1执行结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51hive> insert overwrite table bigdata.user_tag_value partition(module='geography_info')
> select
> user_id,
> 'province' as key,
> province
> from
> (select
> user_id,
> row_number() over (partition by user_id order by time_tag desc) as order_rank,
> address['province'] as province
> from
> bigdata.weblog
> where
> active_name = 'pay') t1
> where
> order_rank = 1;
Query ID = 1015146591_20190107230037_ea3bdeb8-6a0b-4111-bb4c-9df76751b914
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 7
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535253853575_21574, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21574/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21574
Hadoop job information for Stage-1: number of mappers: 6; number of reducers: 7
2019-01-07 23:00:43,782 Stage-1 map = 0%, reduce = 0%
2019-01-07 23:00:52,071 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 6.24 sec
2019-01-07 23:00:54,146 Stage-1 map = 18%, reduce = 0%, Cumulative CPU 17.19 sec
2019-01-07 23:00:55,190 Stage-1 map = 20%, reduce = 0%, Cumulative CPU 60.04 sec
2019-01-07 23:00:57,268 Stage-1 map = 26%, reduce = 0%, Cumulative CPU 66.89 sec
2019-01-07 23:00:58,329 Stage-1 map = 40%, reduce = 0%, Cumulative CPU 77.07 sec
2019-01-07 23:01:00,383 Stage-1 map = 48%, reduce = 0%, Cumulative CPU 90.85 sec
2019-01-07 23:01:02,481 Stage-1 map = 70%, reduce = 2%, Cumulative CPU 98.15 sec
2019-01-07 23:01:03,592 Stage-1 map = 80%, reduce = 7%, Cumulative CPU 108.43 sec
2019-01-07 23:01:04,632 Stage-1 map = 100%, reduce = 10%, Cumulative CPU 110.95 sec
2019-01-07 23:01:05,662 Stage-1 map = 100%, reduce = 19%, Cumulative CPU 111.22 sec
2019-01-07 23:01:06,701 Stage-1 map = 100%, reduce = 43%, Cumulative CPU 117.57 sec
2019-01-07 23:01:07,727 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 143.3 sec
MapReduce Total cumulative CPU time: 2 minutes 23 seconds 300 msec
Ended Job = job_1535253853575_21574
Loading data to table bigdata.user_tag_value partition (module=geography_info)
Partition bigdata.user_tag_value{module=geography_info} stats: [numFiles=7, numRows=40460, totalSize=2632564, rawDataSize=0]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 6 Reduce: 7 Cumulative CPU: 143.3 sec HDFS Read: 1571466260 HDFS Write: 2633278 SUCCESS
Total MapReduce CPU Time Spent: 2 minutes 23 seconds 300 msec
OK
Time taken: 33.794 seconds最后一步,将中间表通过行专列,将其转换成一个大宽表
1
2
3
4
5
6
7
8insert overwrite table bigdata.user_profile
select
user_id,
concat('{', concat_ws(',', collect_set(concat('"', tag, '"', ':', '"', value, '"'))), '}') as json_string
from
bigdata.user_tag_value
group by
user_id;执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34hive> insert overwrite table bigdata.user_profile
> select
> user_id,
> concat('{', concat_ws(',', collect_set(concat('"', tag, '"', ':', '"', value, '"'))), '}') as json_string
> from
> bigdata.user_tag_value
> group by
> user_id;
Query ID = 1015146591_20190107230714_4f1ca497-377e-4c69-9500-23d0640447f8
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1535253853575_21593, Tracking URL = http://bigdata0.novalocal:8088/proxy/application_1535253853575_21593/
Kill Command = /home/hadoop/hadoop-current/bin/hadoop job -kill job_1535253853575_21593
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2019-01-07 23:07:44,411 Stage-1 map = 0%, reduce = 0%
2019-01-07 23:07:51,719 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 3.13 sec
2019-01-07 23:07:55,855 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 13.74 sec
2019-01-07 23:08:02,102 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 22.6 sec
MapReduce Total cumulative CPU time: 22 seconds 600 msec
Ended Job = job_1535253853575_21593
Loading data to table bigdata.user_profile
Table bigdata.user_profile stats: [numFiles=0, numRows=58424, totalSize=0, rawDataSize=0]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 22.6 sec HDFS Read: 14766922 HDFS Write: 8294101 SUCCESS
Total MapReduce CPU Time Spent: 22 seconds 600 msec
OK
Time taken: 49.459 seconds查看一下最终得到的大宽表是怎样的结构:
1
select * from bigdata.user_profile limit 10;
执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13hive> select * from bigdata.user_profile limit 10;
OK
0001528165978481 {"gender":"女","age":"43.0","device_type":"Android","register_day":"2018-05-29"}
0001528166031761 {"gender":"女","age":"44.0","device_type":"WEB","register_day":"2018-04-25","first_order_time":"1527578321393","last_order_time":"1527578321393","order_count":"1","order_sum":"40.0","province":"山西"}
0001528166058390 {"gender":"女","age":"26.0","device_type":"WEB","register_day":"2018-04-09"}
0001528166157577 {"gender":"男","age":"27.0","device_type":"WEB","register_day":"2018-01-10"}
0001531897045258 {"gender":"男","age":"34.0","device_type":"IPhone","register_day":"2018-03-26"}
0001531897084097 {"gender":"女","age":"39.0","device_type":"WEB","register_day":"2018-05-30"}
0001531897098930 {"gender":"女","age":"21.0","device_type":"IPhone","register_day":"2018-02-13"}
0001531897281376 {"gender":"男","age":"21.0","device_type":"IPhone","register_day":"2018-05-30","first_order_time":"1527642284658","last_order_time":"1527642284658","order_count":"1","order_sum":"64.0"}
0001531897292909 {"gender":"男","age":"40.0","device_type":"WEB","register_day":"2018-03-03","first_order_time":"1527639077523","last_order_time":"1527639077523","order_count":"1","order_sum":"25.0"}
0001531897299559 {"gender":"女","age":"35.0","device_type":"IPhone","register_day":"2018-01-07","first_order_time":"1527637397062","last_order_time":"1527637397062","order_count":"1","order_sum":"86.0"}
Time taken: 0.037 seconds, Fetched: 10 row(s)使用大宽表举例:
1
2
3
4
5
6
7
8select
user_id,
get_json_object(profile, '$.gender'),
get_json_object(profile, '$.age'),
get_json_object(profile, '$.province')
from
bigdata.user_profile
limit 10;执行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20hive> select
> user_id,
> get_json_object(profile, '$.gender'),
> get_json_object(profile, '$.age'),
> get_json_object(profile, '$.province')
> from
> bigdata.user_profile
> limit 10;
OK
0001528165978481 女 43.0 NULL
0001528166031761 女 44.0 山西
0001528166058390 女 26.0 NULL
0001528166157577 男 27.0 NULL
0001531897045258 男 34.0 NULL
0001531897084097 女 39.0 NULL
0001531897098930 女 21.0 NULL
0001531897281376 男 21.0 NULL
0001531897292909 男 40.0 NULL
0001531897299559 女 35.0 NULL
Time taken: 0.224 seconds, Fetched: 10 row(s)
总结
使用方式二行列转换的方式的好处:
灵活增加指标而不改动表结构
可以并行计算指标,运行效率高
字段输出顺序灵活可调
用户自定义函数UDF的使用
Hive自带了很多函数,但是还是有些业务场景是hive自带函数无法满足的,这时就需要用根据业务户编写自定义函数以满足业务需要。
根据用户生日解析星座
Hive中并没有将用户生日解析成星座的函数,如果不自定义函数,就需要在sql中写一堆case…when…进行判断,就如:
1 | case...when... |
这种方式可以实现功能,但是每次在这种场景下都要书写这没多sql语句,很麻烦。
可以将这些语句封装成用户自定义函数,每次需要将用户生日转换成星座的时候调用这个自定义的函数就可以了,省力,也不容易出错。
用户自定义函数UDF
用户自定义函数创建步骤:
继承UDF类,并实现evaluate函数
编译成jar包
hive会话中加入jar包
create function定义函数
实例
在MR课程创建的工程中的pom中添加相关依赖,如下:
1
2
3
4
5
6<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
<scope>provided</scope>
</dependency>为防止中文出现乱码,在pom中指定编码格式为UTF-8:
1
2
3
4<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
</properties>编写计算星座的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117package com.bigdata.etl.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.Calendar;
import java.util.Date;
import java.text.SimpleDateFormat;
public class UDFZodiac extends UDF {
private SimpleDateFormat df;
public UDFZodiac() {
df = new SimpleDateFormat("yyyy-MM-dd");
}
public String evaluate(Calendar bday) {
return this.evaluate(bday.get(Calendar.MONTH + 1), bday.get(Calendar.DAY_OF_MONTH));
}
public String evaluate(String bday) {
Date date = null;
try {
date = df.parse(bday);
} catch (Exception e) {
return null;
}
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
return this.evaluate(calendar.get(Calendar.MONTH) + 1, calendar.get(Calendar.DAY_OF_MONTH));
}
public String evaluate(Integer month, Integer day) {
if (month == 1) {
if (day < 20) {
return "摩羯座";
} else {
return "水瓶座";
}
}
if (month == 2) {
if (day < 19) {
return "水瓶座";
} else {
return "双鱼座";
}
}
if (month == 3) {
if (day < 21) {
return "双鱼座";
} else {
return "白羊座";
}
}
if (month == 4) {
if (day < 20) {
return "白羊座";
} else {
return "金牛座";
}
}
if (month == 5) {
if (day < 21) {
return "金牛座";
} else {
return "双子座";
}
}
if (month == 6) {
if (day < 21) {
return "双子座";
} else {
return "巨蟹座";
}
}
if (month == 7) {
if (day < 23) {
return "巨蟹座";
} else {
return "狮子座";
}
}
if (month == 8) {
if (day < 23) {
return "狮子座";
} else {
return "处女座";
}
}
if (month == 9) {
if (day < 23) {
return "处女座";
} else {
return "天秤座";
}
}
if (month == 10) {
if (day < 23) {
return "天秤座";
} else {
return "天蝎座";
}
}
if (month == 11) {
if (day < 23) {
return "天蝎座";
} else {
return "射手座";
}
}
if (month == 12) {
if (day < 23) {
return "射手座";
} else {
return "摩羯座";
}
}
return null;
}
}打包程序上传到bigdata4,并上传到HDFS上:
这里我在打包的时候出了个问题,提示:
1
[ERROR] Failed to execute goal on project etl: Could not resolve dependencies for project netease.bigdata.course:etl:jar:1.0: Could not find artifact org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in nexus-aliyun (http://maven.aliyun.com/nexus/content/groups/public) -> [Help 1]
我把mvn从阿里的源改为官方的后可以正常打包了,如果有相关问题可以参考一下这个方法。
1
2
3
4
5
6[1015146591@bigdata4 ~]$ hadoop fs -mkdir /user/1015146591/hive/jar
[1015146591@bigdata4 ~]$ hadoop fs -put jars/etl-1.0-jar-with-dependencies.jar /user/1015146591/hive/jar/
[1015146591@bigdata4 ~]$ hadoop fs -ls /user/1015146591/hive/jar
Found 1 items
-rw-r----- 3 1015146591 supergroup 439380 2019-01-08 10:16 /user/1015146591/hive/jar/etl-1.0-jar-with-dependencies.jar
[1015146591@bigdata4 ~]$ mvn clean package启动hive,在会话窗口中加载刚刚上传的jar包:
1
2
3
4hive> add jar hdfs:/user/1015146591/hive/jar/etl-1.0-jar-with-dependencies.jar;
converting to local hdfs:/user/1015146591/hive/jar/etl-1.0-jar-with-dependencies.jar
Added [/mnt/home/1015146591/apps/hive-1.2.2/tmp/91095efc-87b4-4b5c-b52d-3e0e886f69ff_resources/etl-1.0-jar-with-dependencies.jar] to class path
Added resources: [hdfs:/user/1015146591/hive/jar/etl-1.0-jar-with-dependencies.jar]创建临时函数:
1
2
3hive> create temporary function udf_zodiac as 'com.bigdata.etl.udf.UDFZodiac';
OK
Time taken: 0.78 seconds在查询语句中使用刚才编写的函数:
1
2
3
4
5
6
7select
user_id,
from_unixtime(cast(birthday/1000 as bigint), 'yyyy-MM-dd'),
udf_zodiac(from_unixtime(cast(birthday/1000 as bigint), 'yyyy-MM-dd'))
from
bigdata.member
limit 20;查看运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29hive> select
> user_id,
> from_unixtime(cast(birthday/1000 as bigint), 'yyyy-MM-dd'),
> udf_zodiac(from_unixtime(cast(birthday/1000 as bigint), 'yyyy-MM-dd'))
> from
> bigdata.member
> limit 20;
OK
0001528166058390 1992-04-26 金牛座
0001531897045258 1984-02-05 水瓶座
0001531897084097 1979-01-15 摩羯座
0001531897369998 1999-02-23 双鱼座
0001531898051786 1983-06-15 双子座
0001531898202634 1982-11-11 天蝎座
0001531898252101 1986-12-26 摩羯座
0001531898353851 2001-05-16 金牛座
0001531898480773 1995-01-10 摩羯座
0001531898489619 1998-03-26 白羊座
0001531898533512 1997-02-13 水瓶座
0011528165770489 1976-09-30 天秤座
0011528165983913 1992-01-02 摩羯座
0011528166026392 1989-10-26 天蝎座
0011528166029056 1974-07-28 狮子座
0011528166125503 1983-02-26 双鱼座
0011528166158037 1995-01-15 摩羯座
0011528166191049 1985-04-20 金牛座
0011528166197979 2001-02-12 水瓶座
0011531897025121 2001-04-22 金牛座
Time taken: 1.258 seconds, Fetched: 20 row(s)
可以看到用户星座已经被成功解析出来了,也就是我们自己编写的函数可是正常使用了。
工程代码
工程代码:点这里 。
Hive优化案例
SQL写法不同,运行的效率也会出现巨大差异
影响运行效率的因素与优化原则
最重要的两个因素(其实也就是影响MR的两个因素,因为Hive的SQL语句最终要转化成MR执行):
Job数量的多少
数据分布是否均衡
有时数据量不是很大,但是需要关联很多张表时,就需要启动很多个job,那么消耗的时间就比较长。
如果数据不能均匀分布在每个结点,而是某一个节点承担了过多的计算任务,那么在其他节点都完成计算任务后,计算任务较多的节点很长时间都没有计算完成,那么整个任务就卡在了这里。
优化方法:
减少Job数量
减少数据倾斜
分区和裁剪
在日常编写HiveSQL时,当对两表做关联的时候,如果涉及到分区表,那么就尽量将分区字段放到子语句当中,这样,两表在做关联的时候数据量已经得到压缩。
另外在select的时候尽量只选取我们需要的字段,这样可以减少读入字段和分区的数目,节省中间存储和数据整合的开销。应尽量减少select *的使用。
例如下面的SQL语句:
1 | select |
避免迪卡尔及积
如果在两表关联时发生多对多的关联,多对多是指关联字段在量表中均多次出现,比如在orders表中,同一个用户可能有多笔订单记录;在用户标签库user_tag_value中同一个用户可能会有多个标签。
这两张表(orders和user_tag_value)以user_id做关联时,就会产生迪卡尔积,就会产生大量的重复记录,这种情况是应该尽量避免的。
避免多对多关联
下面这种SQL应该尽量避免:
1 | select |
替代union
多次使用union会导致hive多次执行去重操作,导致运行效率比较低。
1 | select |
一个更好的替代方法是使用union all,union all与union的差别是union all不会执行去重操作,相同的记录会得到保留,然后在最外层使用一次去重即可。
1 | select |
减少count distinct
在使用count和distinct的时候,每次使用都会调用一个Reduce任务来完成,一个Reduce任务如果处理的数据量过大会导致整个job难以完成。
1 | select |
如果数据量比较大,我们可以使用count…group by来优化:
1 | select |
总结
这就是我在学习Hive过程中的笔记,里面包含的一些建表数据信息存放在这个地址,可以自行下载测试。
对比之前写MapReduce程序和现在使用Hive处理数据,可以发现Hive真的是更装了很多,也简化了很多,非常适合对代码编写不是特别熟悉的分析人员使用,当然开发人员也可以使用Hive来简化数据验证阶段的流程,避免繁琐地编写MapRedcue代码。
总得来说,Hive是个不错的使用SQL语言进行离线数据分析工具。